How can they help slowing down the spread of a decease while preserving users’ privacy?
Introduction
In this second quarter of 2020, the world is facing a new situation with most of the countries in the world being locked down due to the COVID-19 pandemic. Isolating infected people to contain the spread is the fastest way to prevent a global pandemic and is effective, as demonstrated during the Ebola crisis. However, this requires knowing who an infected person has been in contact with. While collection of such data by health authorities is allowed, it is a very slow and resource-consuming process, which is why governments, companies and academics are looking for better solutions to collect those data.
Following our blog post on mobile network technologies that can be used to fight COVID-19, this article will focus on privacy preserving contact tracing applications, and more specifically on the concept and protocols behind them.
Objectives and challenges
Quarantines help preventing the pandemic to spread. In order to know who should be put in quarantine, proximity data need to be collected from infected people. This is currently allowed by the legislation and is performed by the Health Authorities in order to contain the pandemic but also to better understand the key factors of its spreading. Unfortunately, this is currently a slow and resource-demanding process, as it is performed “manually”: an agent is charged with the task of interviewing the infected people to trace back who they have been in contact with. This method is also incomplete, as it is impossible in most cases to remember everyone one has been in contact with, or simply to identify strangers (in public transports for instance). Research suggest that digital contact tracing could help in controlling the spread of the COVID-19 epidemic1. Indeed, people being infected but without symptoms need to be quarantined as well. Using a digital contact tracing solution could help being one step ahead of the virus, and not one step behind. However, designing a privacy preserving contact tracing application is not an easy task.
When designing such a technology, several objectives need to be met:
- The first one, which is probably the main one, is to be able to quickly and efficiently determine who has been in close proximity with an infected person (in an exhaustive manner if possible). Ideally, the solution should also provide insights on the pandemic and help identify key factors in the spreading, helping policymakers to take better measures.
- This should be accomplished while preserving users’ privacy and consent. As stated on the MIT’s solution “Private Kit”, some people are “more afraid of being blamed than dying of the virus.” Users’ privacy should not go away due to the situation.
- The solution should rely on existing and easily available hardware and technologies. There is no time to wait for a new innovation.
- The pandemic has no border. Thus, the solution must be scaled with a world-wide usage in mind. It is unlikely that all countries will happily rely on one unique country to operate the solution. A way to deal with cross-countries infections should then exist.
Designing a solution that meets all these requirements is not an easy task, and challenges exist:
- While it is legally allowed to collect proximity contact data in such a context, the solution should not be usable outside of the scope it has been conceived for. It can be tempting for some entities to take advantage of such a large-scale solution later on to track people when the COVID-19 crisis will be over.
- Given that we are currently in a race against time to develop such solutions, it is not easy to develop it in a secure manner. For instance, using the Trusted Platform Module (TPM) of the phone to perform cryptographic operations is recommended but currently very seldomly done: even though some phones and/or vendors provide TPM or an equivalent like Samsung, it is not the case for all phones on the market yet.
Many entities world-wide have proposed solutions to this problem. Several of them are phone-based and use Bluetooth Low Energy. The next section will present the basic mechanisms on which the applications rely to meet the objectives described above.
DP-3T
It would be impossible and pointless to cover all proposed solutions in an exhaustive manner in such a short article. This is why, we will consider here DP-3T as an example to explain the mechanisms. An overview of projects aiming to track COVID-19 can be found here. The Decentralized Privacy-Preserving Proximity Tracing (DP-3T) is a system proposed by a consortium of experts from several European Universities such as EPFL, ETHZ, KU Leuven, and many others. Two versions have been proposed so far, the second one being a more secure extension of the first one:
- Low-cost decentralized proximity tracing
- Unlinkable decentralized proximity tracing
Approaches like GACT (from Google and Apple) are based on the first one. This is also the one we will base our explanations on for the sake of clarity, but it is to be noted that implementing the second one is recommended, the low-cost version having proven vulnerable to some attacks. The explanations in this post are based on the DP-3T White Paper as of the beginning of May 2020.
Low-cost decentralized proximity tracing
To meet the completeness requirement (logging all contacts), the protocol relies on Bluetooth Low Energy Beacons. The idea is that users have an application installed on their phone which generates “frequently changing ephemeral identifiers” (EphIDs) which are then broadcasted. These IDs are received and stored by phones around the broadcaster along with “contact” information such as the date, the duration and the proximity. It is important to know that EphIDs cannot be linked to the user. EphIDs are indeed generated using a daily key SKt (unique for each user) which is then used in a Pseudo-Random Function to initialize a Pseudo-Random Generator in order to generate n * 16 bytes (n being the number of EphIDs needed for the day and 16 bytes the size of the BLE Beacons’ payload). All EphIDs broadcasted by a phone for a given day t can thus be recovered by only knowing the key SKt. Figure 1 presents such EphIDs exchange between Alice and Bob.

The DP-3T protocol is based on a “pull model”, meaning that non-infected users regularly pull data from a server in order to check whether or not they have been in close contact with someone infected. Going back to our example, if Bob is found infected, he will be asked by the Health Authorities to upload his key SKt and the day t he started to be sick (following keys can be obtained by computing SKt+1 = H(SKt) where H is a cryptographic hash function). Alice’s phone downloads the infected users’ keys and computes the associated EphIDs. If one or more of these IDs match some that are already stored locally, it means that Alice has been in close proximity with an infected person. An arbitrary score is then increased and if it is higher than a given threshold, she is asked to quarantine. What Alice learns is that she has been in contact with an infected person, but she does not learn who.
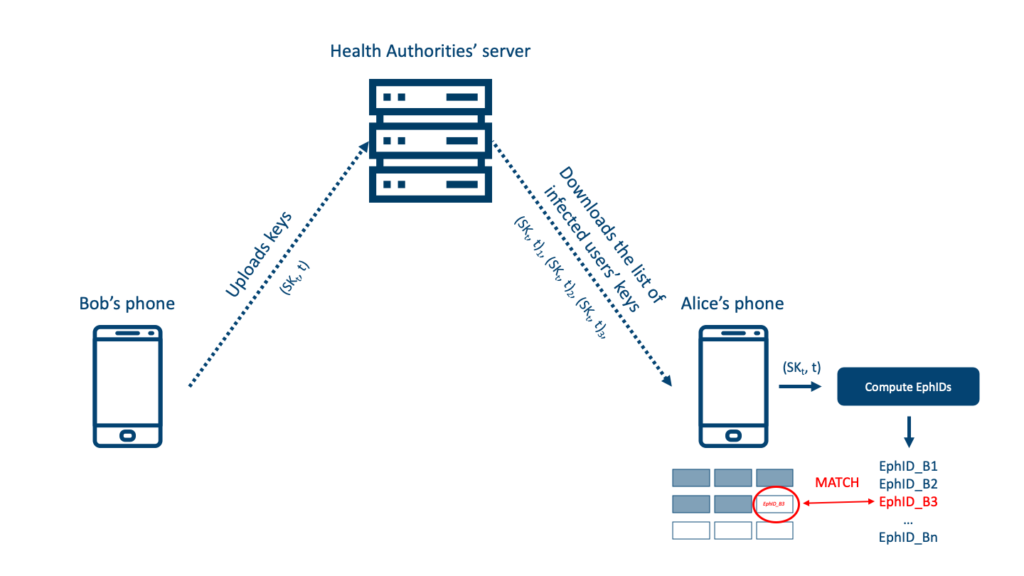
If we sum up what information is shared: users send EphIDs to users around them and those EphIDs can only be computed again when knowing the key SKt which is unique and random for each user. These keys remain on users’ phones only except if they get infected. Even then, the key cannot be linked to a user, meaning that if the server is compromised, attackers won’t get any private information. No other data is collected and data (both on server and phones) is retained for a period of 14 days. Non-infected users are never sending any data to the server.
Epidemics have no border. In order to be scalable, the application should also pull data from the servers of visited countries. That can be configured either manually by the user, or automatically by using GPS data for instance. In order to help epidemiologists better understand the key factors in the epidemic spread, users that have been in contact with an infected person (“at risk” people) can share their data with them, on a voluntarily basis. This data should be enough for the epidemiologists “to build the first-degree contact graph needed for their analysis.”
Security considerations & Limitations
Such widely deployed system can be of great interest for attackers. Governments or companies might have an interest into abusing those to monitor people. Other countries might want to abuse them to create confusion and panic in a rival country, by virtually increasing the number of cases for instance. Let us review some of the weaknesses of the DP-3T system and how they can be addressed.
Having only an EphID and no other information, one cannot link it back to its originating user, but a skilled user can modify his application to log additional meta-data (location, exact time, CCTV, etc.) and use those to infer the identity of an infected person. Indeed, with this additional data an attacker knows exactly where and when an EphID was obtained. If there was only one other person in proximity of the attacker at that moment, the attacker will learn when that person is affected. As explained in the White Paper, this is “possible with any proximity-based notification system.” The unlinkable version uses a Cuckoo Filter to determine whether or not a user has been in closed contact with an infected person. That way, the keys are not shared anymore to all users, and only the collected EphIDs are known.
The usage of a Cuckoo Filter also solves another problem: when people share their key on the low-cost system, they cannot ask for some periods of time to be excluded. However, with Cuckoo Filters, the server choses which EphIDs to include and can thus “hide” the ones broadcasted during a period the infected users do not want to share. People might want to tell to their close friends that they are the one who contaminated them, so that they don’t learn it from the app.
Attackers performing wardriving (driving and capturing signals) can also collect a lot of data and then use those data to make links, or to replay EphIDs. The introduction of a secret sharing scheme in the unlinkable version partially solves that issues as the EphID is split into m beacons, and at least k out of m beacons are needed to recover the complete EphID.
If the server is malicious, location of infected individual can be at risk: by logging meta-data during the key upload, the server can infer information on the user.
Finally, online replay attacks are also possible and cannot be protected against. A state-level attacker could for instance capture the traffic at several places and replaying it live at other locations, generating fake contacts. Similarly, an attacker can jam the Bluetooth signals, thus preventing the app to register contact at all.
These are some examples of elements to consider when designing such an application. The White Paper includes a detailed analysis of the security and privacy implications of both proposed designs.
Conclusion
In a nutshell, designing a privacy preserving contact tracing application is hard, especially under the current circumstances. So far, there are many alternative solutions but not a perfect one. Such applications are however fundamental: even if the world is going through a crisis like never before, it should not mean that people have to give away their privacy. It is however a double-edged sword, because it can be tempting to develop those applications as fast as possible, which can lead to insecure protocols, servers, applications and to catastrophic consequences if misused by powerful attackers. It is then necessary that we keep a cold head and work on a not only privacy preserving but also secure contact tracing application.