En undersøkelse fra det amerikanske analyseselskapet ESG (se grafikk) viser at nesten annenhver store virksomhet samler informasjon tilsvarende >= 6 TB per måned for å støtte analyse og arbeid med informasjonssikkerhet. Mengden innsamlede data til dette formålet har økt betydelig for annenhver virksomhet de siste to år. Men hvilken sikkerhet finnes egentlig i disse enorme datamengdene?

Grafikken fortsetter lenger ned i innlegget.
Big data har blitt mote-ordet for at man besitter mye data på et eller annet. Det er visstnok ulike oppfatninger på hvor mye det må være for å være big, men 44% i undersøkelsen mener de vil kunne kalle grunnlaget som sikkerhetsanalysen baseres på for big data i løpet av de neste to år. Tilsvarende mange er allerede av denne oppfatningen i dag. Det er uansett snakk om storskala lagring og analyse av sikkerhetsrelatert informasjon, og ikke minst at slik analyse må gå fort nok.
Overvåking og logging (jeg er ikke noen tilhenger av ordet «monitorering») kan bl.a. gi kvantifiserbare måltall for trusselnivået, informasjon om angrepsflater, angripere, etc., og ikke minst støtte kritisk etterretning når et sikkerhetsbrudd faktisk har inntruffet. Derimot er ikke overvåking så veldig effektivt til å si noe om de tingene man ikke oppfatter; det som på en eller annen måte kamuflerer seg eller opptrer utenfor definerte rammer for overvåkingen. Det er her man kunne se for seg at big data vil kunne utgjøre en forskjell, nettopp i å finne mønster i dataene, med støtte av kunstig intelligens og avanserte visualiseringer. Resultatet er forhåpentligvis grunnlag for å komme angriperne i forkjøpet – ihvertfall ved neste anledning.
Et problem med å overvåke og logge slike uhorvelige datamengder, er imidlertid at det vil skalere forholdsvis dårlig. Det er slett ikke gratis å sitte på tera- og petabytes med data som nok i svært mange tilfeller er verdiløse. Man klarer ikke å finne sammenhengene som ligger der, man lagrer for mye unyttig informasjon, og/eller analysen går rett og slett for sakte. 35% i undersøkelsen mener at det oppstår for mange falske positive identifikasjoner av sikkerhetshendelser ved hjelp av denne typen analyser. 41% mener samtidig at de trenger å samle inn enda mer data…
Teksten fortsetter nedenfor grafikken.
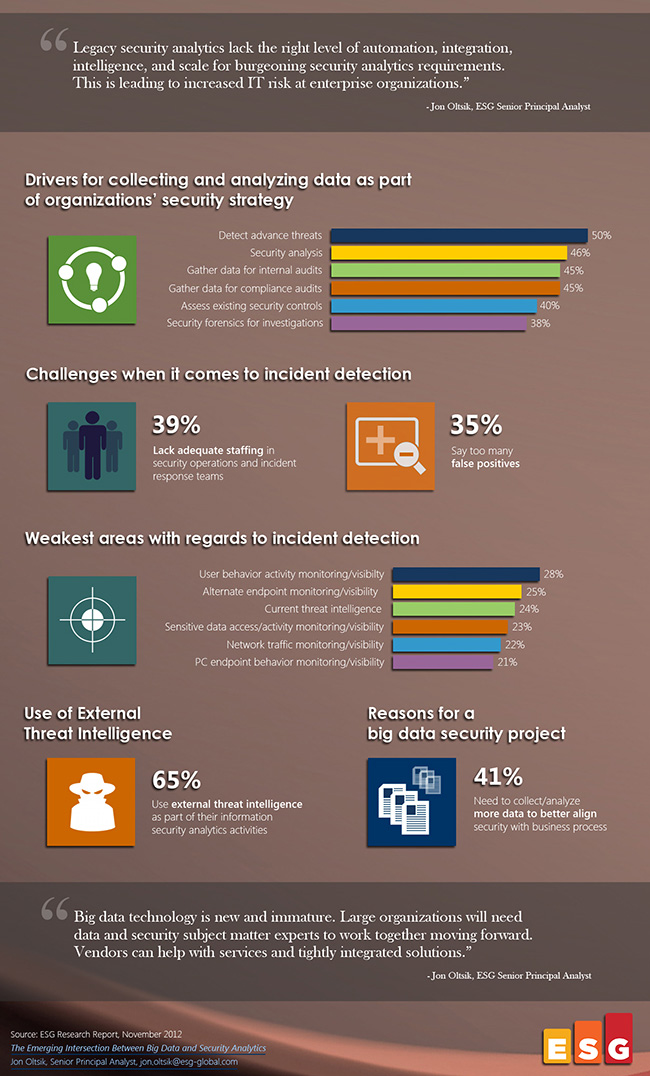
Det andre problemet med å overvåke tilnærmet alt er sikkerheten. Dersom uvedkommende får tilgang til loggene, er det plutselig mulig at de sitter på nok informasjon om systemene til å utføre svært målrettede angrep. Kanskje inneholder til og med loggene sensitive virksomhetsdata i seg selv, og dette kan jo da lekke uten at man er klar over det. Hvis ikke man overvåker overvåkingssystemene også, da…
Mange kaller menneskene som bruker systemet for den aller største sikkerhetstrusselen. Det er liksom brukerne som gjør feil og lar seg manipulere – og ja, det er ofte tilfellet. God sikkerhetskultur blant brukerne er viktig, og overvåking som varsler om mistenkelig oppførsel og fysiske bokser som settes inn i nettverket og filtrerer/sjekker trafikk gir også beskyttelse mot mange typer angrep – men slett ikke alle.
Sikker programvareutvikling handler derimot om at færre sårbarheter kan gjøre seg gjeldende i systemene dine – slik de er konstruert fra grunnmuren og opp. Ved å tenke på sikkerheten fra første stund og holde et jevnt høyt fokus i hele utviklingsprosjektet, utvikler man ganske enkelt sikrere systemer. Man logger i tillegg gjerne på mer fornuftige måter, og man sørger for at loggene ikke lekker sensitiv informasjon. Man kan i tillegg hjelpe de stakkars brukerne til å gjøre riktige valg og eventuelt tenke før de klikker, hvis det da absolutt må være nødvendig – for brukersentrert utvikling er også interessant fra et sikkerhetsperspektiv.
Takk til min kollega Per Håkon Meland for innspill til dette innlegget.